Face Mask Detection with Yolo v4

Introduction
In early 2020, the world faced the coronavirus pandemic which would forever change our world. This respiratory disease caused large scale societal changes and destroyed the economies of many countries. One of the earliest preventative measures recommended by most healthcare authorities has been people to wear a mask to limit exposure to respiratory particles. Despite high recommendations, there has been large resistance to wearing a mask. However, many locales have adopted mask wearing policies including the requirements to wear masks in public indoor spaces.
With the wonders of modern technology, we can build models to help monitor in real time mask wearing compliance. We can quickly check who is in compliance for more automated solutions into preventative measures to faster end this pandemic. Yolo v4 is one such machine learning model which was developed for high speed use cases with object detection. Using this model, it would be possible to load it into a webcam for real time inferencing to better remotely understand the risks of interacting with people.
The goal of this project is to understand the feasibility of using object detection models to detect face mask compliance and subsequent serving of the model using attached video capture sources such as a webcam.
![]()
Data Description
The dataset originally was downloaded from kaggle. These are 853 images with varying numbers of people wearing masks, not wearing masks, or wearing masks incorrectly. The images include typical worn face masks, face masks boxes, and strange masks being worn. Additionally of note, there is a strong bias towards images of East Asians wearing masks.
Modeling using Yolo v4
Yolo v4 is a relatively new object detection model which was designed for fast inferencing. Yolo is specifically a one stage object detection model which scans through the image directly for possible regions of interests as opposed to having a region proposal network with two stage detection models. The input images are fed into a backbone layer and a neck layer before going through the final layer to create the bounding boxes and subsequent classification.
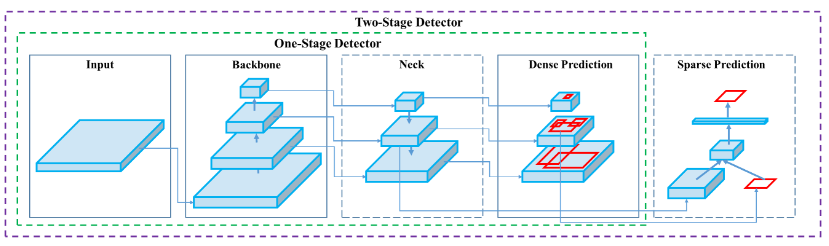 Figure 1 - General Model Architecture of One Stage and Two Stage Object Detection Models
Figure 1 - General Model Architecture of One Stage and Two Stage Object Detection Models
The model also includes multiple features called the “bag of freebies” and “bag of specials” are part of the general architecture. These include a mosiac data augmentation, DropBlock regularization, mish activation function, and more.
 Figure 2 - Example of Mosiac Image Augmentation
Figure 2 - Example of Mosiac Image Augmentation
Many of the features of the model leads it to have superior performance than many other detection models in terms of average precision and inferencing speed. This high precision and speed gives us the opportunity to use this model in a more real time use case as opposed to many other different models.
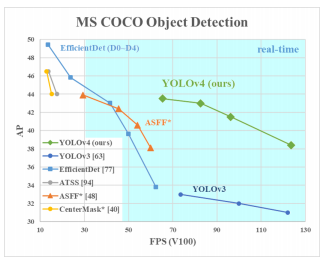 Figure 3 - Inferencing Speed vs Average Precision for multiple Detection Models
Figure 3 - Inferencing Speed vs Average Precision for multiple Detection Models
Results
Using all of the images and using base hyperparameters, we get a mAP(mean Average Precision) of about 95% after 8 hours. We notice through some examples that the model overall performs very well but suffers from some issues with distance and facial angles.
The photos below are some examples from images sourced from unsplash.
 Figure 2 - The model correctly identifies everybody in the photo as wearing masks.
Figure 2 - The model correctly identifies everybody in the photo as wearing masks.
 Figure 3 - The model correctly classifies the barber as wearing a face mask and the client as not wearing a mask.
Figure 3 - The model correctly classifies the barber as wearing a face mask and the client as not wearing a mask.
 Figure 4 - The model can detect instances of the cartridge type respirators.
Figure 4 - The model can detect instances of the cartridge type respirators.
Model Deployment
Using OpenCV, it is possible to run this algorithm in real time using a web cam. The model weights in yolo is first converted into tensorflow compatible weights. Afterwards, OpenCV is used to continuously capture video while simultaneously running inferrance for real time inferencing.
References
- https://machinelearningmastery.com/object-recognition-with-deep-learning/
- https://github.com/theAIGuysCode/tensorflow-yolov4-tflite
- https://jonathan-hui.medium.com/map-mean-average-precision-for-object-detection-45c121a31173
- https://colab.research.google.com/drive/1_GdoqCJWXsChrOiY8sZMr_zbr_fH-0Fg?usp=sharing#scrollTo=9ket44SxkdBu